
Zero-shot vs few-shot prompts
This blog is part of work done by Shouvik Dey, an intern at DeepDive Labs during summer 2024. Analysis on BoolQ Dataset
The world of Generative AI, powered by Large Language Models (LLMs), is indeed fascinating! The rapid advancements in this technology open up exciting possibilities for text-based tasks that were previously limited to individual NLP models. What makes LLMs particularly intriguing is their ability to perform a vast array of tasks with higher accuracy and flexibility, all through prompt engineering.

Zero shot prompting is instructing a large language model (LLM) on a task without any specific training data for that task
In this blog, we explore how different types of prompts—namely, Zero-shot and Few-shot prompting integrated with Chain of Thought—yield varying outcomes. Zero shot prompting is instructing a large language model (LLM) on a task without any specific training data for that task, whereas Few Shots prompting is providing the LLM with a few examples along with your instructions. The instruction used here is Chain of Thoughts, which is a way to guide large language models (LLMs) through their reasoning process, by breaking down complex tasks , focusing on relevant details, and improving accuracy and clarity. By simply improving the prompt template, we can enhance both accuracy and overall results.
For this experiment, I used the BoolQ benchmark dataset and selected a random subset of 252 records. BoolQ is a benchmark dataset for Boolean question answering, where each question is based on a given passage and must be answered with only boolean response true or false. This dataset gained popularity to understand inference ability of language models.
BoolQ dataset example
The boolQ dataset can be extended to several real life applications – Imagine in a supermarket you wait to pick up items for a recipe and you can simply ask, does this recipe require milk?Passage
Persian (/ˈpɜːrʒən, -ʃən/), also known by its endonym Farsi (فارسی fārsi (fɒːɾˈsiː) ( listen)), is one of the Western Iranian languages within the Indo-Iranian branch of the Indo-European language family. It is primarily spoken in Iran, Afghanistan (officially known as Dari since 1958), and Tajikistan (officially known as Tajiki since the Soviet era), and some other regions which historically were Persianate societies and considered part of Greater Iran. It is written in the Persian alphabet, a modified variant of the Arabic script, which itself evolved from the Aramaic alphabet.Question: Do Iran and Afghanistan speak the same language?
Answer: True
In the GenAI era, there are several models that have been used to solve the boolQ QnA task. In this blog we have used prompts to achieve the same task. Prompt-tuning was done using the Gemini model, by configuring the model. We have used two prompting techniques

Few Shots prompting is providing the LLM with a few examples along with your instructions
Zero-shot prompt, i.e., The prompt used does not contain examples or demonstrations. The zero-shot prompt directly instructs the model to perform a task without any additional examples to steer it.
Prompt combining few-shot example and chain of thought(CoT): Few-shot prompting technique includes in-context learning where the prompt provides examples to steer the model to better performance. Chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. It is said CoT works better when combined with few-shot prompting to get better results on more complex tasks that require reasoning before responding, which is relevant to the Bool QnA task.
The zero shot prompt template that was used for the model is as follows:
zero_shot_template = """I am an NLP engineer working on machine comprehension. Using information from a given passage, I am interested to find the answer for a given question. However the answer derived must be strictly on true or false. If there is no answer in the passage, please return unknown.Passage given: {passage}Question about the passage: {question}Provide answer in the following JSON format{{"answer": <Only true or false>"explanation": <rationale for chosen the answer, always return as a string>}}“””
The few-shots prompt, improved with Chain of Thoughts, was:
few_shot_cot_template = """I am an NLP engineer working on machine comprehension. Using information from a given passage, I am interested to find the answer for a given question. The answer derived must be strictly on true or false. Here are few examplesPassage : "While some 19th-century experiments suggested that the underlying premise is true if the heating is sufficiently gradual, according to contemporary biologists the premise is false: a frog that is gradually heated will jump out. Indeed, thermoregulation by changing location is a fundamentally necessary survival strategy for frogs and other ectotherms."Question: "does a frog jump out of boiling water?"Answer : TruePassage : "The pardon power of the President extends only to an offense recognizable under federal law. However, the governors of most of the 50 states have the power to grant pardons or reprieves for offenses under state criminal law. In other states, that power is committed to an appointed agency or board, or to a board and the governor in some hybrid arrangement (in some states the agency is merged with that of the parole board, as in the Oklahoma Pardon and Parole Board)."Question : "can the president pardon someone convicted of a state crime?"Answer : FalsePassage : "The Constitution of India designates the official language of the Government of India as Hindi written in the Devanagari script, as well as English. There is no national language as declared by the Constitution of India. Hindi is used for official purposes such as parliamentary proceedings, judiciary, communications between the Central Government and a State Government. States within India have the liberty and powers to specify their own official language(s) through legislation and therefore there are 22 officially recognized languages in India of which Hindi is the most used. The number of native Hindi speakers is about 25% of the total Indian population; however, including dialects of Hindi termed as Hindi languages, the total is around 44% of Indians, mostly accounted from the states falling under the Hindi belt. Other Indian languages are each spoken by around 10% or less of the population."Question : "is hindi the national language of india?"Answer : TruePassage : "In finance, the time value (TV) (extrinsic or instrumental value) of an option is the premium a rational investor would pay over its current exercise value (intrinsic value), based on the probability it will increase in value before expiry. For an American option this value is always greater than zero in a fair market, thus an option is always worth more than its current exercise value.. As an option can be thought of as 'price insurance' (e.g., an airline insuring against unexpected soaring fuel costs caused by a hurricane), TV can be thought of as the risk premium the option seller charges the buyer--the higher the expected risk (volatility ⋅ (\displaystyle \cdot ) time), the higher the premium. Conversely, TV can be thought of as the price an investor is willing to pay for potential upside."Question : "can the time value of an option be negative?"Answer : FalseExtract the answer for the below question based on the passage given.Follow these instructions before answering to avoid errors:1. Passage Comprehension: Read and comprehend the context of the passage provided2. Question Understanding: Read the question carefully, ensuring a clear understanding of what is being asked in relation to the passage.3. Contextual Alignment: Align the details from the passage with the question by identifying the relevant information that supports or contradicts the question.4. Avoid Ambiguity: Provide a definitive true or false response based on the evidence within the passage. If there is no answer in the passage, please return unknown.5. Review and Refine: Review the answer to ensure it accurately reflects the information presented in the passage and effectively addresses the question.Passage : {passage}Question : {question}Provide answer in the following JSON format{{"answer": <Only true or false>"explanation": <rationale for chosen the answer, always return as a string>}}"""
The confusion matrices of the two prompts for the records excluding the unknown tags are shows below:
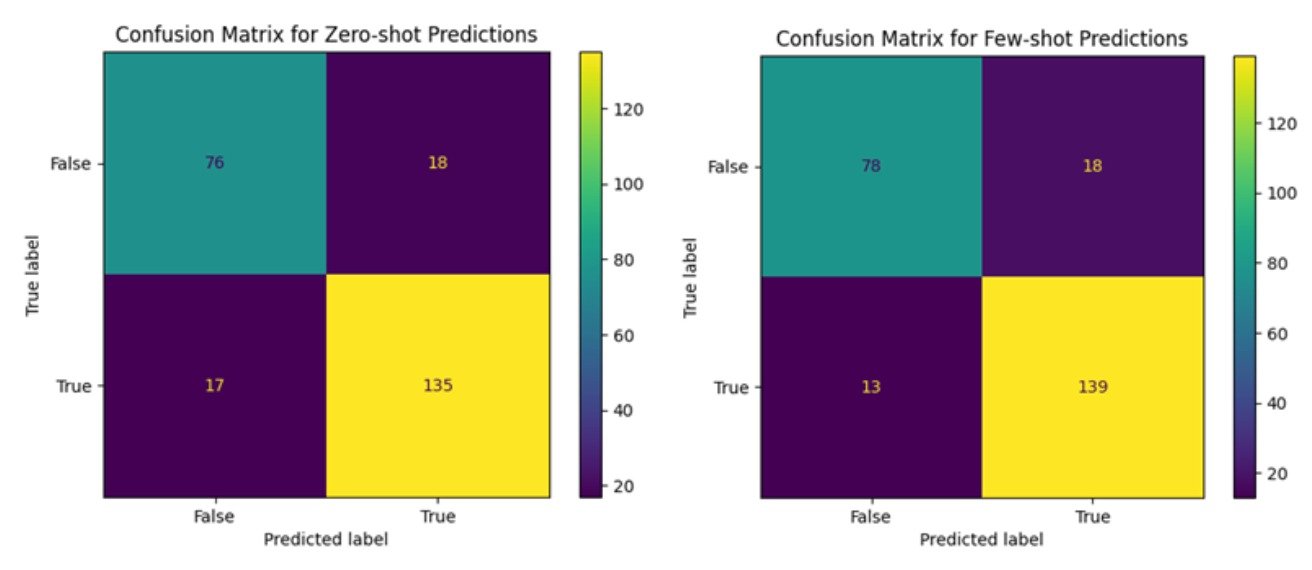
From the evaluation metrics we can infer:
Both models exhibit high precision and recall.
Few-shot has a slightly higher recall (0.9145) than zero-shot (0.8882), indicating better identification of true positives.
Few-shot achieves a higher F1 score (0.8997) and accuracy (0.875) compared to zero-shot (F1: 0.8852, Accuracy: 0.8577).
The above highlights a balanced improvement in handling positive and negative cases. Few-shot learning, enhanced by the Chain of Thoughts prompt, leverages examples, providing context and improving understanding. This context enhances the model's ability to handle complex questions and variability in data. By incorporating examples into the prompt, the few-shot approach enhances recall, F1 score, and accuracy, demonstrating the power of prompt engineering in LLMs. These findings highlight the potential of LLMs to revolutionise text-based tasks through effective prompt optimization.
A notable aspect of our model's performance is the classification of certain responses as "unknown." This typically occurs when the provided passage lacks clear information needed to answer a query. For example, when asked if the film "The Mountain Between Us" is based on a true story, the model responded with "unknown" because the passage only detailed the film's production and cast, without mentioning its basis on real events. Similarly, the question "Is the AR-10 an assault rifle?" also returned an unknown answer, reflecting the absence of specific military classification in the passage. Addressing these unknowns is crucial as they highlight areas where our model requires further refinement to make educated guesses or seek additional context. To mitigate this, we could incorporate more nuanced examples into the few-shot training to teach the model to extrapolate from available information and use logical deductions to fill in the gaps, enhancing its overall interpretive capabilities. This shows that Bool QnA is a good way to perform LLM "evals" to validate LLM-powered enterprise applications.
Our approach misclassified a total of 35 rows using the Zero Shot approach and 31 with the Few Shot method. Notably, 28 misclassifications were common across both models. To dive deeper, we analyzed these misclassified instances by compiling datasets that include the passages, related questions, and answers—both predicted and actual.
Some examples of common False Negatives
Marines and the Navy: The question "Is the Marines a part of the Navy?" led to a false negative error due to the passage's ambiguity about the Marines being a branch of the armed forces that operates with the Navy but not as part of it. This example highlights the need for clearer passages or prompts that incorporate general knowledge to resolve such ambiguities.
Mathematical Ratios: Another false negative occurred with the question "Does the order of numbers in a ratio matter?" The passage provided a correct description of ratios but the model misinterpreted the importance of order, demonstrating a gap in logical processing. It is also well known that LLM are good at logical reasoning as LLM are models that are trained to predict the next word fundamentally!
Some examples of common False Positives
Soft Tissue Injuries and Sprains: The passage describing soft tissue injuries included sprains as a subset. However, the question "Is soft tissue damage the same as a sprain?" resulted in a false positive because the model failed to distinguish between a general category and a specific instance within it.
Naming of the Color Orange: The question "Is the fruit orange named after the color?" also led to a false positive. The passage ambiguously stated the relationship between the fruit and the color, causing confusion for the models about the origin of the name. The passage talks about the colour orange and finally ends with a phrase, “It is named after the fruit of the same name.” This is the Reversal Curse, that describes the LLMs inability to reverse causal statements they are trained on as these models rely heavily on statistical patterns of the data on which they are trained.
Examples where few-shot excelled:
Excretory System Functionality:
Passage: "The liver detoxifies and breaks down chemicals, poisons, and other toxins that enter the body. It transforms ammonia into urea or uric acid, which are then expelled from the body."
Question: "Is the liver part of the excretory system?"
Zero-Shot Answer: False. The model misinterpreted the liver’s functions, focusing narrowly on detoxification without recognizing its role in expelling waste.
Few-Shot Answer: True. With the benefit of a structured CoT example, the model correctly identified the liver's function in waste expulsion, a critical aspect of the excretory system.
Insight: The CoT prompt makes the model “think” beyond the passage and provide a complete answer, not restricted to the passage.
2. Historical Events in U.S. Congress:
Passage: "The filibuster was used in the U.S. House of Representatives until 1842, which then implemented a rule limiting debate duration."
Question: "Can a filibuster take place in the house?"
Zero Shot Answer: True. The model incorrectly applied past conditions to the present.
Few Shot Answer: False. The model correctly recognized that the historical change permanently altered the rules, preventing current filibusters in the House.
Insight: The CoT prompt makes the model bring in information from beyond the passage to provide the right answer.
The one example where zero-shot excelled:
Understanding Energy Units:
Passage: "The joule is also a watt-second and the common unit for electricity sales to homes is the kilowatt-hour (kWh), which is equal to 1000 watts times 3600 seconds or 3.6 megajoules."
Question: "Is a joule the same as a watt?"
Zero Shot Answer: False. The model correctly understood that a joule is a unit of energy (watt-second), while a watt is a unit of power, representing energy per unit time.
Few Shot Answer: True. The CoT model mistakenly equated the joule directly with a watt, ignoring the crucial difference between energy and power. This error demonstrates the potential pitfalls of Few Shot learning when nuanced distinctions are crucial.
Insight: There is nothing specific in the few-shot prompt that made it fail. However, this example makes us question if the answers will remain consistent across small variations in the questions.
In conclusion, our analysis of Zero Shot vs Few Shot prompting techniques for the BoolQ task highlights their respective strengths and areas for improvement. The classification of some responses as "unknown" underscores the need for more refined and diverse few-shot training examples and the inclusion of nuanced examples that enable the model to make educated guesses and draw logical conclusions from available data.
Our deep dive into misclassifications revealed that while both models shared common errors, their responses differed significantly in certain contexts. The Few Shot model, armed with Chain of Thought prompting, excelled in cases like the excretory system functionality and historical events in U.S. Congress, where it could extend beyond the passage to provide accurate answers. This suggests that CoT prompting is particularly effective in contexts where integrating broader knowledge and logical reasoning is critical. By understanding where each technique excels and falls short, we can tailor our approach to not only improve the model’s accuracy but also enhance its applicability across a wider range of real-world scenarios.