
Limitations of a Single-Tool Approach (I/II)
Traditional ML vs. LLM-based text classification
If the only tool you have is a hammer, you tend to see every problem as a nail.
-Abraham Maslow
The world of GenAI, powered by these Large Language Models (LLM) is indeed exciting! Many enterprises are actively looking into opportunities to use them for increasing their productivity. However, they also tend to think that it is a magic pill that will solve all problems! This is why, in some fields there is a frenzy on, “AI replacing our jobs”, “Tech layoffs are happening because AI can now code” etc.. etc.. In some fields like customer support, that may be the trend, but in other areas, I can assure you, it is not even close!
After one of the internal training sessions we had, where we talked about using a template LLM-as-a-judge for a use case that we have been working on, I decided to do my own experiment to compare the performance of LLM vs. traditional ML model for a simple classification task. I used the Spam SMS dataset from the NUS SMS corpus. The messages originate from Singaporeans and mostly from students attending the University and were collected from volunteers who were made aware that their contributions were going to be made publicly available.
After dropping duplicates, there were 5169 SMS in total that were labelled as SPAM and HAM classes. As in any real dataset, the percentage of HAM was 87.37%, i.e., higher, then the percentage of SPAM (12.63%) I did not do any exploratory data analysis and went on to build a model with the labelled dataset. As required for any ML modelling, the dataset was split into 80/20 for train/test and the split was stratified. The TF-IDF vectorizer was used to encode the SMS into sparse vectors which were then modelled using Multinomial Naive Bayes Algorithm. Grid search was used to search through different options of the hyperparameters. The final optimised model was built using 2000 most frequently occurring unigrams and bigrams, with no stop words removed.
X = spam['message']
y = spam['label']
# Split the data into the training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=42)
pipe_tvec = Pipeline([
('tvec', TfidfVectorizer()),
('nb', MultinomialNB())
])
pipe_tvec_params = {
'tvec__max_features': [2_000, 3_000, 4_000, 5_000],
'tvec__stop_words': [None, 'english'],
'tvec__ngram_range': [(1,1), (1,2)]
}
gs_tvec = GridSearchCV(pipe_tvec, # what object are we optimizing
param_grid = pipe_tvec_params, # what parameters values are we searching
cv=5) # 5-fold cross-validation.
# Fit GridSearch to training data.
gs_tvec.fit(X_train, y_train)
gs_tvec.best_params_
{'tvec__max_features': 2000,
'tvec__ngram_range': (1, 2),
'tvec__stop_words': None}
gs_tvec.score(X_test, y_test)
0.97775
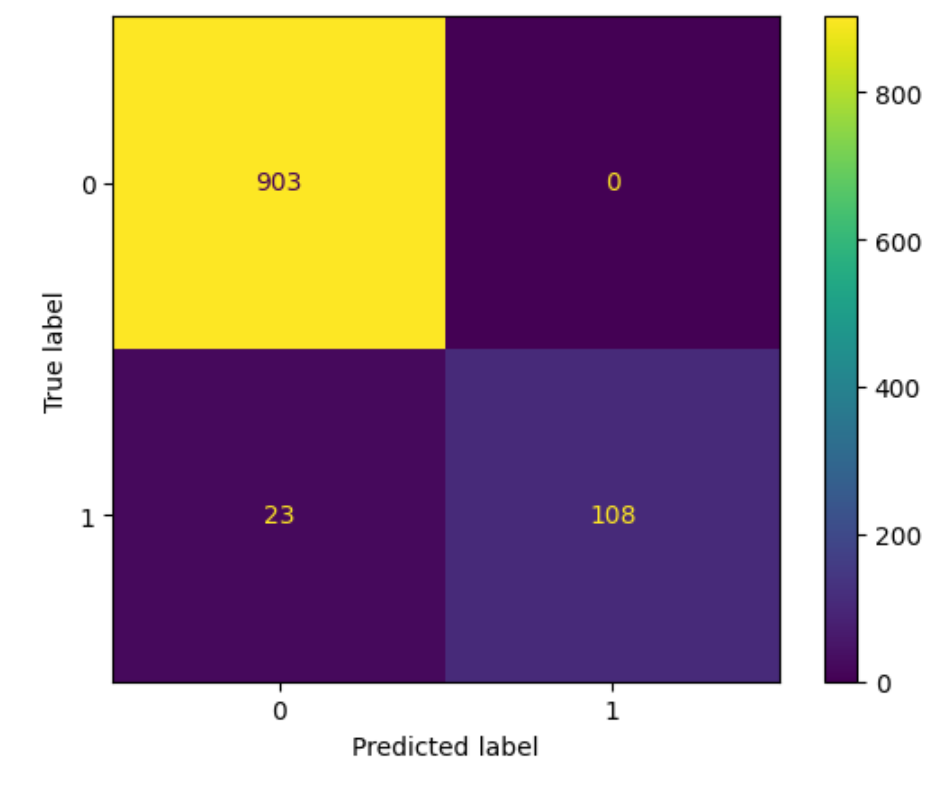
This is the confusion matrix
|
True Positives Predicted as SPAM, and actually SPAM |
True Negatives Predicted as HAM, and actually HAM |
Total |
|---|---|---|
|
108
|
903 | 1034 |
|
False Positives Predicted as SPAM, but actually HAM |
False Negatives Predicted as HAM, but actually SPAM |
|---|---|
| None | 23 |
Following the classic text classification model, next we attempt to do classification using LLMs. The mistral model, which is a Mixture of Expert (MOE) model, was used to generate a spam vs ham classification. The model is hosted in hugging face and available to use once you have signed up for a token. The following prompt was used to achieve the text classification task. However, when using LLM it's always a good idea to not just do the task but also get an explanation for the specific categorization.
classify_prompt = """
I am a NLP engineer working on text classification.
I would like you to classify the short message service (SMS) text into spam or ham.
You will be given an SMS text and your task is to provide a 'Tag' and your rationale for the Tag as a text.
Provide your output as follows:
Output:::
Tag: (your classification, Ham or Spam or unknown)
Evaluation: (your rationale for chosen Tag, as a text)
Here are few examples
SMS: FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv
Tag: Spam
Evaluation: The message contains typical spam keywords like "FreeMsg" and "std chgs to send" and has a suggestive tone, indicating it is likely spam.
SMS: Oh k...i'm watching here:)
Tag: Ham
Evaluation: The SMS text does not contain any suspicious or malicious content. It is a casual message that is likely to be sent between friends or acquaintances. The text does not contain any links or requests for personal information, which are common characteristics of spam messages.
You MUST provide values for 'Tag:' and 'Evaluation:' in your answer.
Here is the SMS text
SMS: {SMSText}
Provide your output in the format.
Output:::
Tag:
Evaluation:
"""
Only the test data was used to generate the tags using the above prompt. Here are the results:
|
True Positives |
True Negatives |
False Positives |
False Negatives |
Tagged Unknown |
LLM generates gibberish | Total |
|---|---|---|---|---|---|---|
| 122 | 807 | 52 | 7 | 45 | 1 | 1034 |
Other than the standard TP, TN, FP and FN, two new categories or errors have emerged.
1. SMS text that generated gibberish as output from the LLM. There was only one such SMS and it was
Congratulations ur awarded either £500 of CD gift vouchers & Free entry 2 our £100 weekly draw txt MUSIC to 87066 TnCs www.Ldew.com1win150ppmx3age16 2. SMS text that was tagged unknown as the LLM was not sure if its a HAM or SPAM. It is unclear as to why that single SMS did not get a response. My guess would be that some encoding issue with the text that it caused the LLM to spit out the responses as:

Encoding Issue that may have caused LLM Gibberish
I wonder what kind of pre-processing that can be done to avoid this?
As majority (all but 1) of the unknown corresponded to HAM, all unknowns were labelled as HAM to generate the confusion matrix
